 主流反爬
主流反爬
#########################################################
基于bs4的爬虫技术
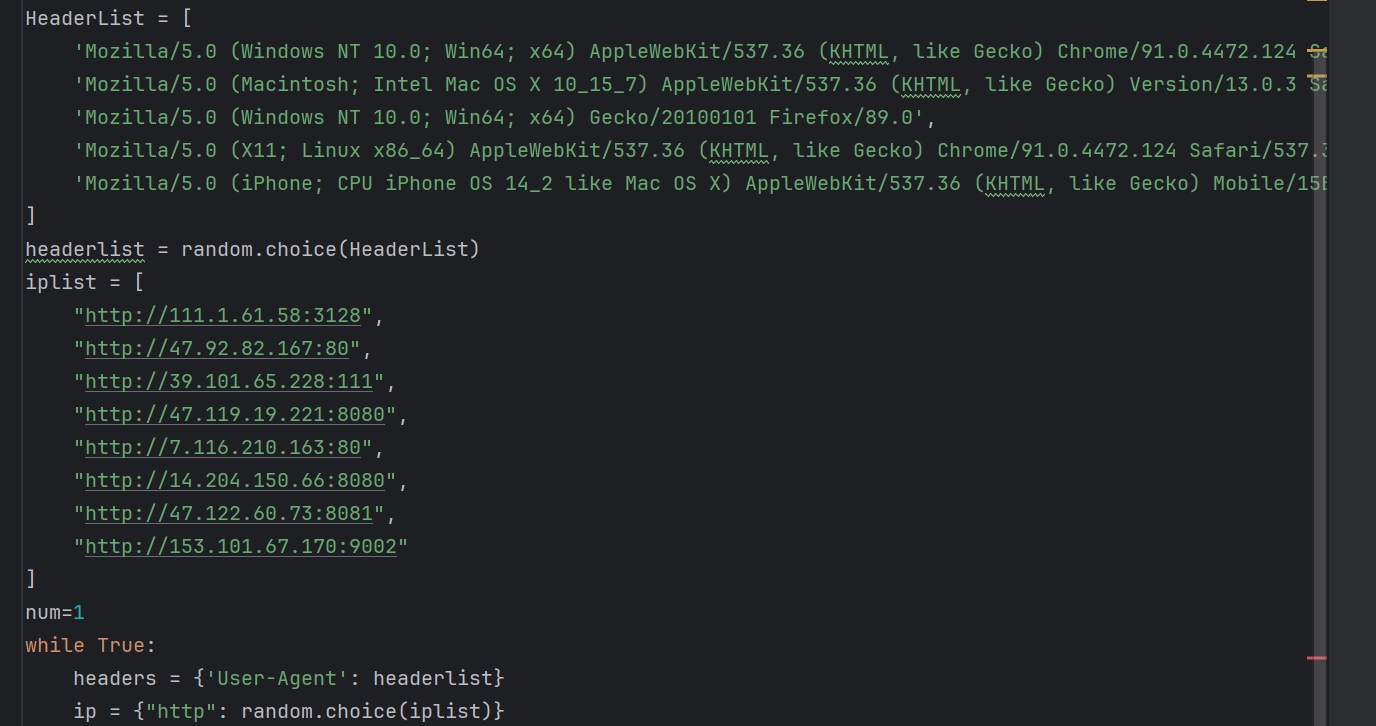
首先创建请求头包含User-agent和ip防止被ban

创建爬虫请求并且将获得的文本用beautifulsoup转换
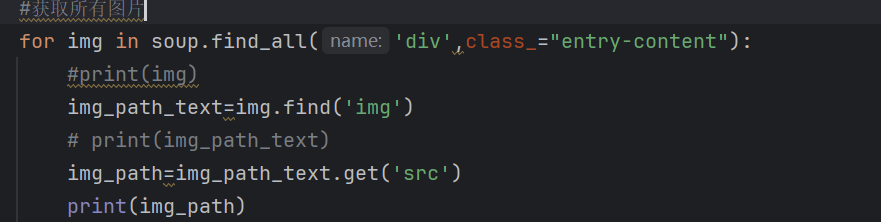

根据网页的源码进行分析,选择自己想要的部分用for...in....来取一个页面中所有格式相同的元素,逐级选择
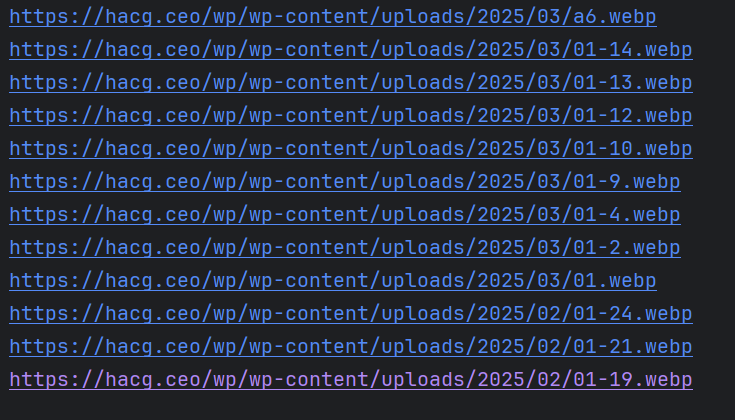 获取到内面中所有的漫画封面(存在问题点进去后是乱码,在原网站复制图片链接访问也是乱码)
获取到内面中所有的漫画封面(存在问题点进去后是乱码,在原网站复制图片链接访问也是乱码)
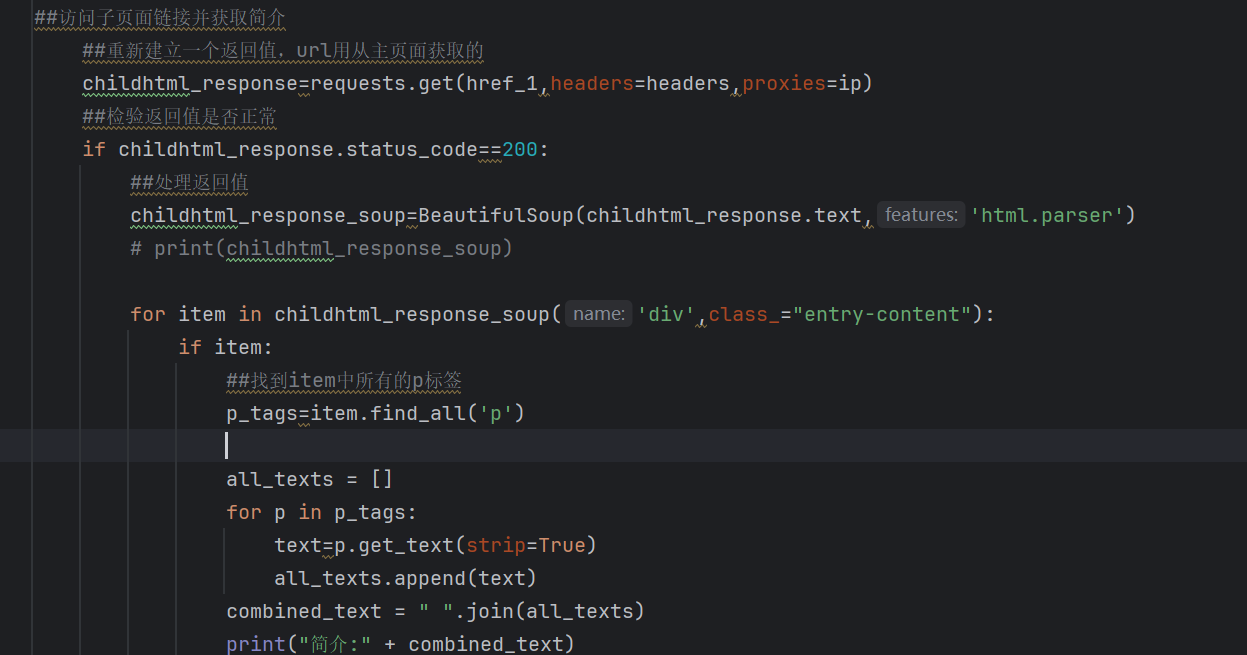
创建访问子页面的部分,思路是在主页获取页面新建立一个获取网页的返回

接下来是数据库部分
插入数据库并且结束数据库
